Let's have a look at the anatomy of a PromQL query. PromQL has operators, functions, selectors, and more, but let's not get bogged down by those details in this post. Let's instead look at the overall nature of a query: How are PromQL queries structured and typed, and how are they evaluated over time?
This blog post assumes that you have a very rough idea of what a PromQL query and the Prometheus data model looks like, but nothing beyond that. Let's get started!
PromQL is a nested functional language
Unlike SQL or some other query languages that tend to be more imperative (SELECT * FROM ...), PromQL is a nested functional language. That means that you describe the data you are looking for as a nested set of expressions that each evaluate (without side effects) to an intermediary value. Each intermediary value is used as an argument or operand of the expressions surrounding it, while the outer-most expression of your query represents the final return value that you get to see in a table, graph, or similar use case.
An example query could look like this:
# Root of the query, final result, approximates a quantile.
histogram_quantile(
# 1st argument to histogram_quantile(), the target quantile.
0.9,
# 2nd argument to histogram_quantile(), an aggregated histogram.
sum by(le, method, path) (
# Argument to sum(), the per-second increase of a histogram over 5m.
rate(
# Argument to rate(), the raw histogram series over the last 5m.
demo_api_request_duration_seconds_bucket{job="demo"}[5m]
)
)
)A PromQL expression is not just the entire query, but any nested part of a query (like the rate(…) part above) that you could run as a query by itself. In the example above, each commented line represents one expression.
When you analyze the same query in PromLabs' PromLens query visualizer, this nested structure of expressions containing sub-expressions becomes especially clear:
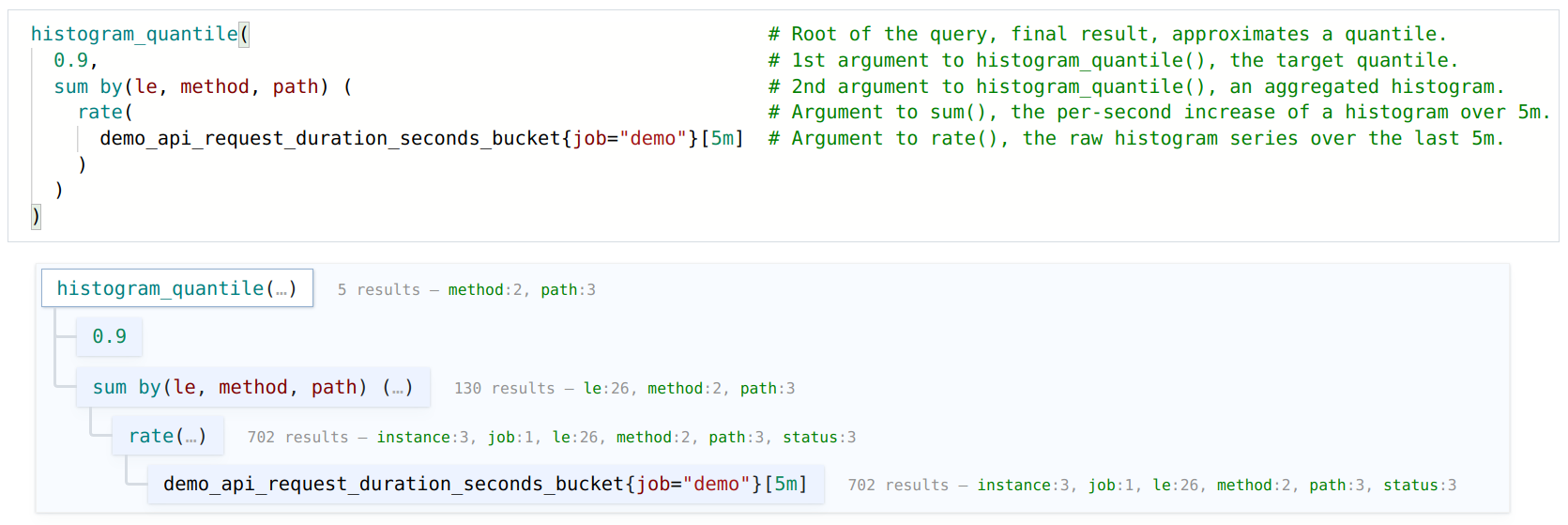
In PromLens, you can click on each tree node to evaluate its sub-expression separately, to get an idea of what data you are working with in each part of the nested expression tree.
Expressions are typed, but maybe not like you think
There are two concepts of "type" that come up in Prometheus:
- The type of a metric, as reported by a scraped target: counter, gauge, histogram, summary, or untyped.
- The type of a PromQL expression: string, scalar, instant vector, or range vector.
PromQL completely ignores metric types and only concerns itself with expression types: Each expression has a type, and each function, operator, or other type of operation requires its arguments to be of a certain expression type. For example, the rate() function requires its argument to be a range vector, but rate() itself evaluates to an instant vector. Thus in turn, the result of rate() can only be used in places that expect instant vectors.
The possible expression types in PromQL are:
- string: A string like
"I am a string!". These only show up as arguments to certain functions (likelabel_join()) and are otherwise not used much in PromQL. - scalar: A single numeric value like
1.234without label dimensions. You'll see these as numeric parameters to functions such ashistogram_quantile(0.9, …)ortopk(3, …), and also in arithmetic operations. - instant vector: A set of labeled time series, with one sample for each series, all at the same timestamp. Instant vectors can result either directly from a TSDB time series selector like
node_cpu_seconds_total, or from any function or other transformation that returns them.node_cpu_seconds_total{cpu="0", mode="idle"} → 19165078.75 @ timestamp_1 node_cpu_seconds_total{cpu="0", mode="system"} → 381598.72 @ timestamp_1 node_cpu_seconds_total{cpu="0", mode="user"} → 23211630.97 @ timestamp_1 - range vector: A set of labeled time series, with a range of samples over time for each series. There are only two ways to produce range vectors in PromQL: by using a literal range vector selector in your query (like
node_cpu_seconds_total[5m]), or by using a subquery (like<expression>[5m:10s]). Range vectors are useful for when you want to aggregate over the behavior of a series over a specified time window, like you would withrate(node_cpu_seconds_total[5m])to calculate the average per-second rate of increase over the last 5 minutes of thenode_cpu_seconds_totalmetric.Note: The timestamps of the samples in a range vector are not necessarily the same across all series. For example, samples from different targets (and thus different scrapes) will usually have slightly different timestamps.node_cpu_seconds_total{cpu="0", mode="idle"} → 19165078.75 @ timestamp_1, 19165136.3 @ timestamp_2, 19165167.72 @ timestamp_3 node_cpu_seconds_total{cpu="0", mode="system"} → 381598.72 @ timestamp_1, 381599.98 @ timestamp_2, 381600.58 @ timestamp_3 node_cpu_seconds_total{cpu="0", mode="user"} → 23211630.97 @ timestamp_1, 23211711.34 @ timestamp_2, 23211748.64 @ timestamp_3
But what of metric types? If you have already used PromQL, you might know that certain functions only work on metrics of a specific type! For example, the histogram_quantile() function only works on histogram metrics, rate() only works on counter metrics, and deriv() only works on gauges. But PromQL does not actually check that you pass in the right type of metric - these functions will often happily run and return something nonsensical for the wrong type of input metric, and it is up to the user to pass in time series that obey certain assumptions (like having a sensical le label in case of a histogram, or increasing monotonically in case of a counter). However, in the future we will likely see UIs such as PromLens try to warn you if you pass an incompatible metric type to a function.
How does time come in? Range and instant queries!
You may have noticed that the only references to time in PromQL queries are relative references (such as [5m], looking back 5 minutes). So how do you specify an absolute graph time range, or a timestamp at which to show query results in a table? In PromQL, such time parameters are sent separately from the expression to the Prometheus query API, and the exact time parameters depend on the type of query you are sending. Prometheus knows two types of PromQL queries: instant queries and range queries.
Instant queries
Instant queries are used for table-like views, where you want to show the result of a PromQL query at a single point in time.
An instant query has the following parameters:
- The PromQL expression.
- An evaluation timestamp.
The expression is evaluated at the evaluation timestamp, and any data selectors in the query are allowed to select data stretching from that timestamp back into the past (foo[1h] selects the last hour of data for foo series), but never into the future (foo[-1h] is not valid PromQL). Accessing a window of past data is often useful for computing aggregates like rates or averages over a period of time.
An instant query can return any valid PromQL expression type (string, scalar, instant and range vectors).
Example instant query:
Let's look at one instant query example to see how its evaluation works. Imagine evaluating the expression http_requests_total at a given timestamp. http_requests_total is an instant vector selector that selects the latest sample for any time series with the metric name http_requests_total. More specifically, "latest" means "at most 5 minutes old and not stale", relative to the evaluation timestamp. So this selector will only yield a result for series that have a sample at most 5 minutes prior to the evaluation timestamp, and where the last sample before the evaluation timestamp is not a stale marker (an explicit way of marking a series as terminating at a certain time in the Prometheus TSDB).
If we run this query at a timestamp where there are recent samples, the result will contain two series with a single sample each:

Note that the output timestamp of each returned sample is no longer the original sample timestamp, but gets set to the evaluation timestamp.
Imagine executing this same query at a timestamp where there is a >5m gap in data before the timestamp:

In this case, the query would return an empty result, since all matching samples are too old to be included.
Range queries
Range queries are mostly used for graphs, where you want to show a PromQL expression over a given time range. A range query works exactly like many completely independent instant queries that are evaluated at subsequent time steps over a given range of time. Of course this is highly optimized under the hood and Prometheus doesn't actually run many independent instant queries in this case.
A range query has the following parameters:
- The PromQL expression.
- A start time.
- An end time.
- A resolution step.
After evaluating the expression at every resolution step between the start and end time, the individually evaluated time slices are stitched together into a single range vector. Range queries allow passing in either instant-vector-typed or scalar-typed expressions, but always return a range vector (the result of the scalar or instant vector being evaluated over a range of time).
Example range query:
If we evaluate the example expression from above as a range query, it would look like this (with the example query's resolution step being 2.5 minutes):

Note how each evaluation step behaves exactly like an independent instant query, and each independent instant query has no concept of the overall range of the query. Note also how some subsequent resolution steps end up selecting the same underlying raw sample as their output sample value, when that raw sample happens to still be the latest one (and not older than 5 minutes) for both of those steps.
The final result in this case will be a range vector that has samples for the two selected series over a range of time, but that will also contain gaps in series data at some of the time steps.
In conclusion...
Hopefully this blog post has given you a better idea of the overall structure of PromQL queries, the type checking (or lack thereof) that is going on, and the evaluation of queries over time. Comment below with any questions or remarks you have, and stay tuned for more posts on PromQL!
Comments powered by Talkyard.